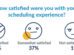
The government and many healthcare leaders are pushing for more interoperability and data sharing in healthcare. While this is great and has the potential to...
Patient Matching

The following is a guest article by Rachel Podczervinski MS, RHIA, Vice President of Professional Services at Harris Data Integrity Solutions. Efforts to...

When it comes to HIEs, each one is different. They often have distinct missions, and many states have multiple HIEs trying to approach electronic information...

One of the most interesting and challenging topics in healthcare lately has been around identity. Certainly this was brought to the forefront thanks to COVID...

The following is a guest article by Joaquim Neto, Chief Product Officer at Verato. More than 200 million doses of the COVID-19 vaccine have been administered...
The following is a guest article by Andy Aroditis, CEO, NextGate. The COVID-19 pandemic is continuing to accelerate across the United States, with record...
The following is a guest article by Alvin Loh, senior director of product at Redox. No nation on earth has a more illustrious record of space exploration than...

Provider Matching has always sounded like something that should be relatively easy, but like everything else in healthcare, it is more complex than it appears...

I think we’re all interested to see what kind of funding is going to be made available in the COVID-19 spending package that is happening. Tom Leary, VP...
Patient matching problems are persistent across healthcare organizations and continue to pose patient safety risks, according to a new survey addressing these...